※本コラムは「2016年のJ1リーグ全試合データを機械学習し、2017年の展望を予測する(1)」の続きです
スタッツデータを用いてゴール数を機械学習する前に、少し寄り道して、スタッツデータから見えてくる、各チームの特徴の違いに注目してみる。
単純にゴール数と相関のあるスタッツデータだけを比較しても各チームで傾向が異なる。たとえば、鹿島アントラーズ、川崎フロンターレ、浦和レッズ、そして比較として、年間順位上位3チームとスタイルが異なる横浜F・マリノスにおける、ゴール数との相関上位のスタッツデータは下記の通りとなった。

※枠内シュート数・アシストなど、ゴールに直結する指標は除く。
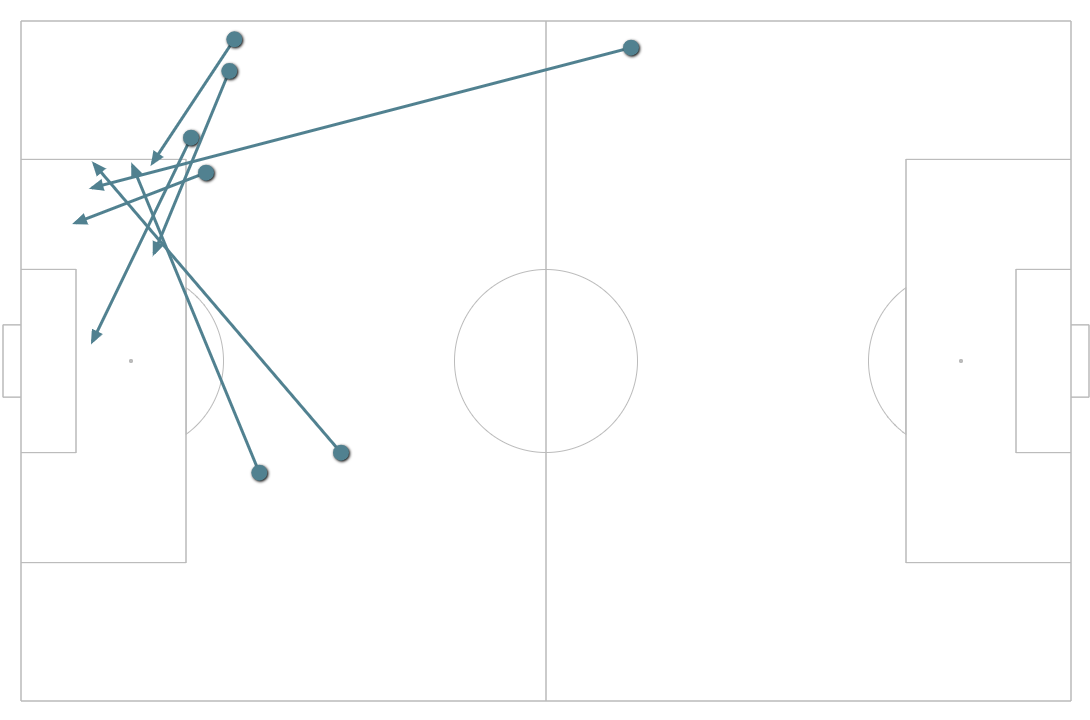
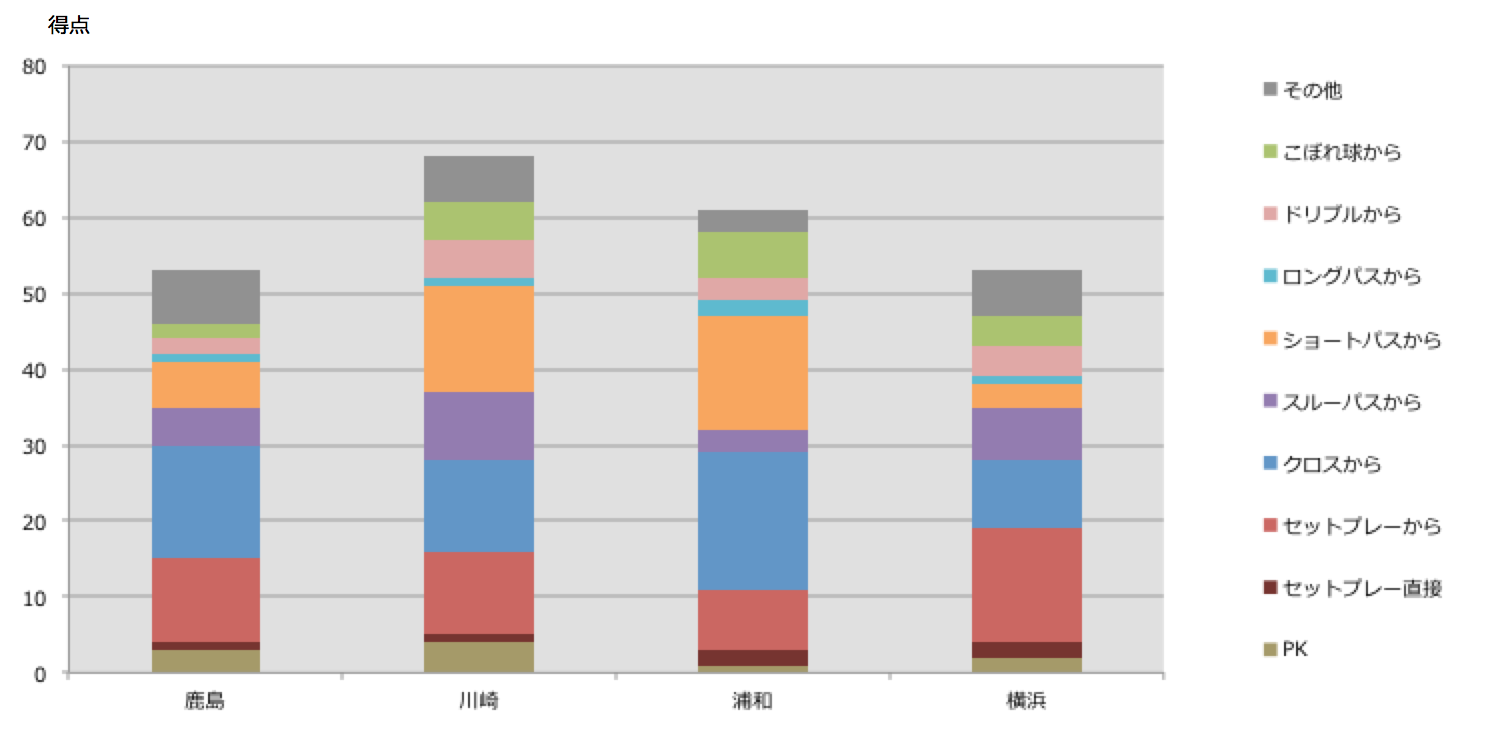
鹿島アントラーズはFKクロス、およびミドルサードから(への)のパス、川崎フロンターレは、インターセプトの回数、およびワンタッチプレー、浦和レッズはスルーパス、敵陣での空中戦勝利、がゴールとの相関が高くなった。一方、横浜F・マリノスはセットプレーからの得点が他のチームと比較しても高く、ゴールとの相関上位3指標は全てセットプレー関連となった。参考までに下記が2016年シーズンにおける、上記4チームのゴールパターンごとのゴール数となる。浦和レッズはスルーパスからの直接ゴールは少ないものの、スルーパスとゴールとの相関が高くなったのは、スルーパスで崩してからのゴール、などがあったためと思われる。
このような、チームごとに異なるプレースタイルを直感的に可視化するために、自己組織化マップ(SOM:Self Organization Map)という機械学習手法を用いてみる。自己組織化マップとは、多次元の情報をもとに、前情報なしに類似しているものを自動的に近くにマッピングする手法となる。
次にランダムに初期値を決める。
※下記では、ユニット中の波は、多次元のパラメータを表す。わかりやすいように擬似的に色で表現。
(似ているパラメータは、似ている色)
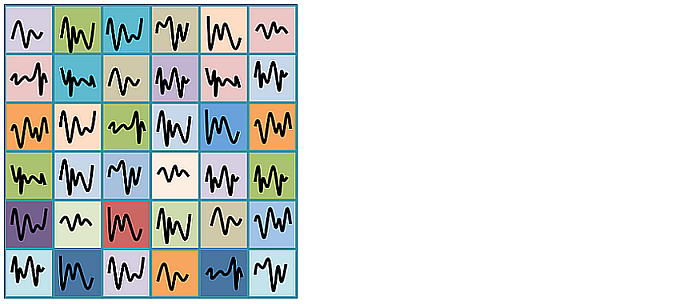
各チームを、各ユニットの値(最初はランダムに決められている)が、もっとも近いものを探して、マッピングする。
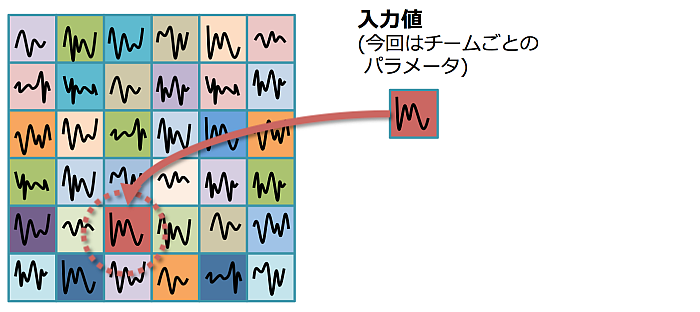
マッピングした際に周辺値を入力値で上書きするとともに、周辺も薄く上書きする。(距離に応じて上書きが決まる関数を定義)
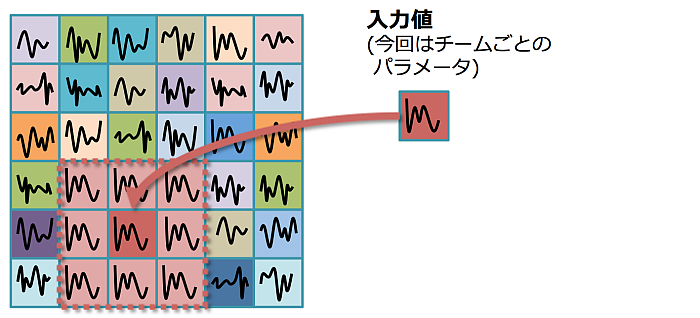
同様の作業を全チーム分の入力値で繰り返す。
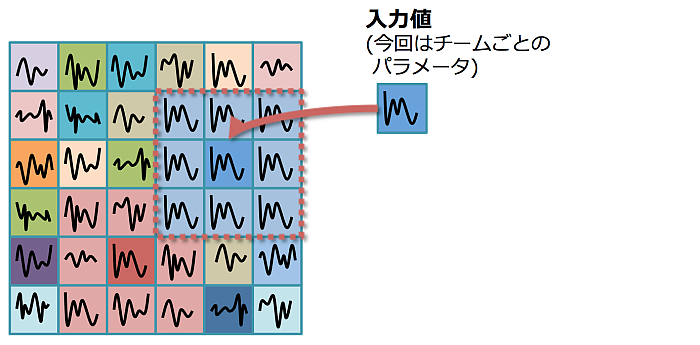
すべての入力値をマッピングし終えたら、それを初期値として再度上記フローを任意の回数、学習し直す。
すると、前情報を知らなくても、似たパラメータの情報(似たスタッツデータのチーム)は自ずと組織化(近くにマッピング)されていくという手法となる。
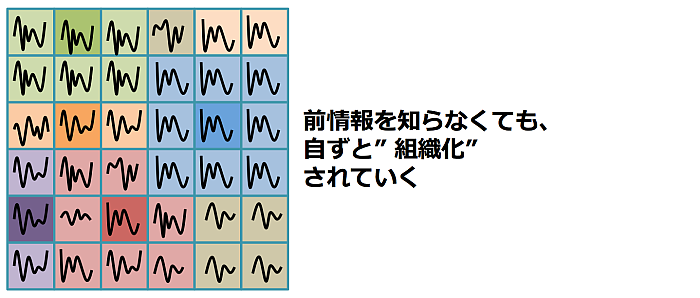
結果は下記のようになった。2016年の年間順位上位3チームである、鹿島アントラーズ、浦和レッズ、川崎フロンターレは遠くにマッピングされており、ゴールとの相関が高い項目でもみたとおり、それぞれ異なるプレースタイルのようだ。大宮アルディージャとFC東京、ベガルタ仙台とサガン鳥栖は、データ上では、プレースタイルが近い、という結果となった。

このように各チームでプレースタイルは異なるのであれば、攻撃的なチーム・守備的なチームそれぞれがあると思われ、対戦相手によって期待されるゴール数は異なりそうだ。
「2016年のJ1リーグ全試合データを機械学習し、2017年の展望を予測する。(3)」へ続く。

Columns

Graphics