



























































HOME » 【論文解説】サッカーは退屈になりつつある? ~欧州サッカーにおける「意外性」の変遷~
本ウェブサイトではこれまでデータを使用したオリジナルの記事を掲載してきました。
サッカーに対する研究をさらに進めるため、今後は大学や研究機関などで行われた「アカデミックなサッカー研究」についても紹介していく予定です。
最先端のサッカー研究について紹介することで、読者のみなさまにより深く、より楽しいサッカー情報をお伝えしていきます。
今回紹介する研究は、欧州において試合結果の「予測しやすさ」がどのように移り変わってきたのかについて調査したものです。
文:NAOKI
Twitter: @naokiwifruit
●はじめに
サッカー市場における移籍金高騰が叫ばれて久しいです。
これまでの移籍金最高額は、ブラジル代表FWネイマールがバルセロナからパリ・サンジェルマンに移籍した際の約280億円となっており、とてつもない金額まで膨れ上がっています。
このような過度な収益化が試合面にまで影響を与えていると指摘する声もあります。
オックスフォード大学のMaimoneらは、過度な収益化やチーム間の格差が試合に与えている影響について実際に調査を行いました。
V. M. Maimone et al. "Football is becoming boring; Network analysis of 88 thousands matches in 11 major leagues." arXiv:1908.08991 (2019).
●本論文の3つのポイント
・欧州主要11リーグ26年分の試合データを利用し、試合結果の「意外性」の経年変化を調べた。
・機械学習の手法を利用し、「意外性」を算出した。
・最近の試合になるほど結果が予測しやすくなっていることを示した。
●研究のモチベーション
サッカーは世界で最も人気のあるスポーツだと言われています。
なぜサッカーは人気なのでしょうか?
その理由の一つとして「意外性」が挙げられます。
サッカーでは予想外の出来事が日常的に起きています。
例えば、昨シーズンのUEFAチャンピオンズリーグにおいて、下馬評が低かったアヤックスが強豪チームを次々と下し、ベスト4まで進出して世間を驚かせました。
ここでのMaimoneらの関心は、今後もサッカーは意外性により人気を維持するのか、それとも、意外性が低いスポーツとなり人気を失っていくのか、ということです。
彼らは欧州主要11リーグ26年分の試合結果をデータとして利用し、試合結果の「予測しやすさ(≒意外性を測る指標)」が年を経るごとにどう変化したのか調査しています。
●「予測しやすさ」をどのように算出するか?
まず、試合の「予測しやすさ」を求めるため、試合結果を予測する機械学習モデルを作成しています。
「機械学習」とは、過去のデータの特徴からコンピュータが自動で判断基準やルールを学び、課題を実行することを指します。
「人工知能」の一種だと考えていただいて構いません。
今回の場合、「課題」は「サッカーの試合結果を予測する」ことになります。
試合結果を正確に予測するモデル=良いモデルということになりますが、逆に考えると、良いモデルが結果を予測しきれなかった試合は、意外性が高かったと解釈することもできます。
●単純な「Dyadicモデル」
彼らが最初に作成したモデルは、ホームチームとアウェイチームどちらが勝つかを予測する単純なものでした。
モデルを学習させるためのデータとして、各チームの直近N試合の「パフォーマンス」が使われています。
違うリーグ同士の試合を比較するため、参照する試合の情報量をリーグ間で統一する必要が出てきます。
そのため、直近の試合数Nをリーグの総試合数Tで割った値を統一することにより、参照する過去の試合数をリーグ毎に設定しています。
n = N ÷ T
また、各チームの「パフォーマンス」として下記に示す”Dyadic Score”を指標として使用しています。
このDyadic Scoreはチームがどれだけ勝点を得られたかを表す指標となっており、以下の式で算出されます。
Dyadic Score = (直近のN試合でチームが得た勝ち点) ÷ (N試合で理論上得ることができた勝ち点の最大値)
ホームチームとアウェイチームのDyadic Scoreの差を試合ごとに算出し、モデルを学習させるデータとして利用しています。
しかしながら、このデータには過去の対戦相手との実力差が反映されていません。
強いチームに勝っていようが弱いチームに勝っていようが、同じ量のポイントを得ることになってしまうため、強さの指標としては不十分です。
そこで彼らは、ネットワークサイエンスという学問の手法を用い、より適切な学習データを作成することにしました。
●より厳密な「Networkモデル」
まず、過去N試合の結果を元にして、有向ネットワークと呼ばれるものを作成します。
ネットワークとは、集団の構成員を頂点として表し、頂点の間の関係性を辺で表したものです。
今回のケースでは、構成員(頂点)は「チーム」であり、関係性(辺)は「試合結果」を表しています。
特に、辺で表す関係に方向性があるものは有向ネットワークと呼ばれ、ソーシャルネットワークやウェブページの解析に利用されてきました。
サッカーの試合結果を表す際にも便利であり、実際にイングリッシュプレミアリーグ 18-19シーズンの試合結果を有向ネットワークで表したのが下図になります。
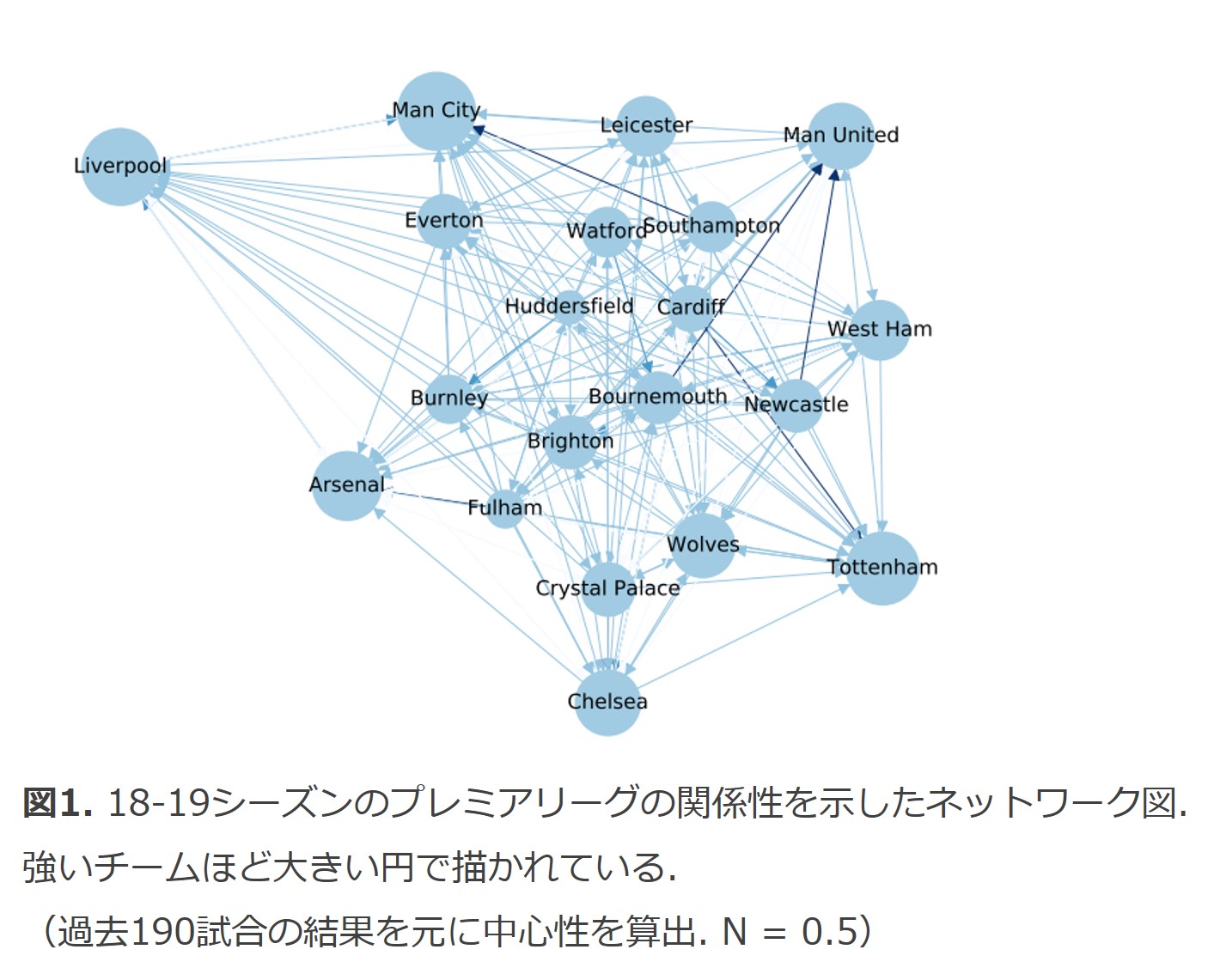
辺は敗者から勝者に向けて伸びており、勝者が得た勝ち点によって重みがつけられています。
次に、作成したネットワーク図を元に各チームの中心性を求めていきます。
中心性とは、各頂点の重要性を評価するための指標です。
今回のケースでは、「各チームの強さ」を評価する指標となります。
たくさん勝っているチームは他のチームから多くの辺を向けられて中心性の値が高くなるので、各チームの強さを評価するのに使えるわけです。
中心性にも様々な種類がありますが、今回は固有ベクトル中心性と呼ばれるものが採用されています。
固有ベクトル中心性は、そのチームに向けて辺を張っているチームの中心性も考慮に入れて計算される指標になっています。
高い中心性を持つチームから辺を向けられている場合、そのチームの中心性も高くなるよう定義されているため、強いチームに勝っているチームほど値が高くなります。
このように、固有ベクトル中心性は勝ち点に縛られない、チーム間の実力差が反映された指標となります。
Networkモデルでは、ホームチームとアウェイチームの固有ベクトル中心性の差を訓練データとして利用し、モデルの学習に使用しています。
●モデルの学習
Dyadicモデル用とNetworkモデル用の訓練データがそれぞれ揃いました。
次に、教師データとして実際の試合結果(ホームチームが勝利したか否か)を使い、それぞれのモデルを学習させています。
どちらのモデルにおいてもロジスティック回帰という手法が採用されており、ホームチームの各試合における勝利確率を予測します。
モデルの性能評価を行ったところ、DyadicモデルよりNetworkモデルの方が優れていたため、以降の検証では主に後者が使われています。
●試合の「予測しやすさ」はどのように移り変わってきたのか?
ようやく本題です。
Maimoneらは作成したNetworkモデルを使用し、試合の予測可能性の経年変化を調査しました。
「試合結果の予測しやすさ」を測る指標として、Area Under Curve (AUC)を利用しています。
AUCは機械学習分野ではお馴染みの指標です。
本来はモデルの性能を評価するための指標であり、AUCの値が高いほど良いモデルとされています。
今回はそれを逆手に取り、モデルにデータを与えた時のAUCの値が高いリーグほど試合結果が予測しやすいと考えたのです。
「モデルに試合結果を高精度で予測されるリーグは、意外性が少ない」という解釈になります。
この利用法は議論が巻き起こりそうですが、ひとまず話を進めます。
調査の結果を示したのが図2です。リーグごとにグラフが用意されており、青色の線がAUCの経年変化を示しています。
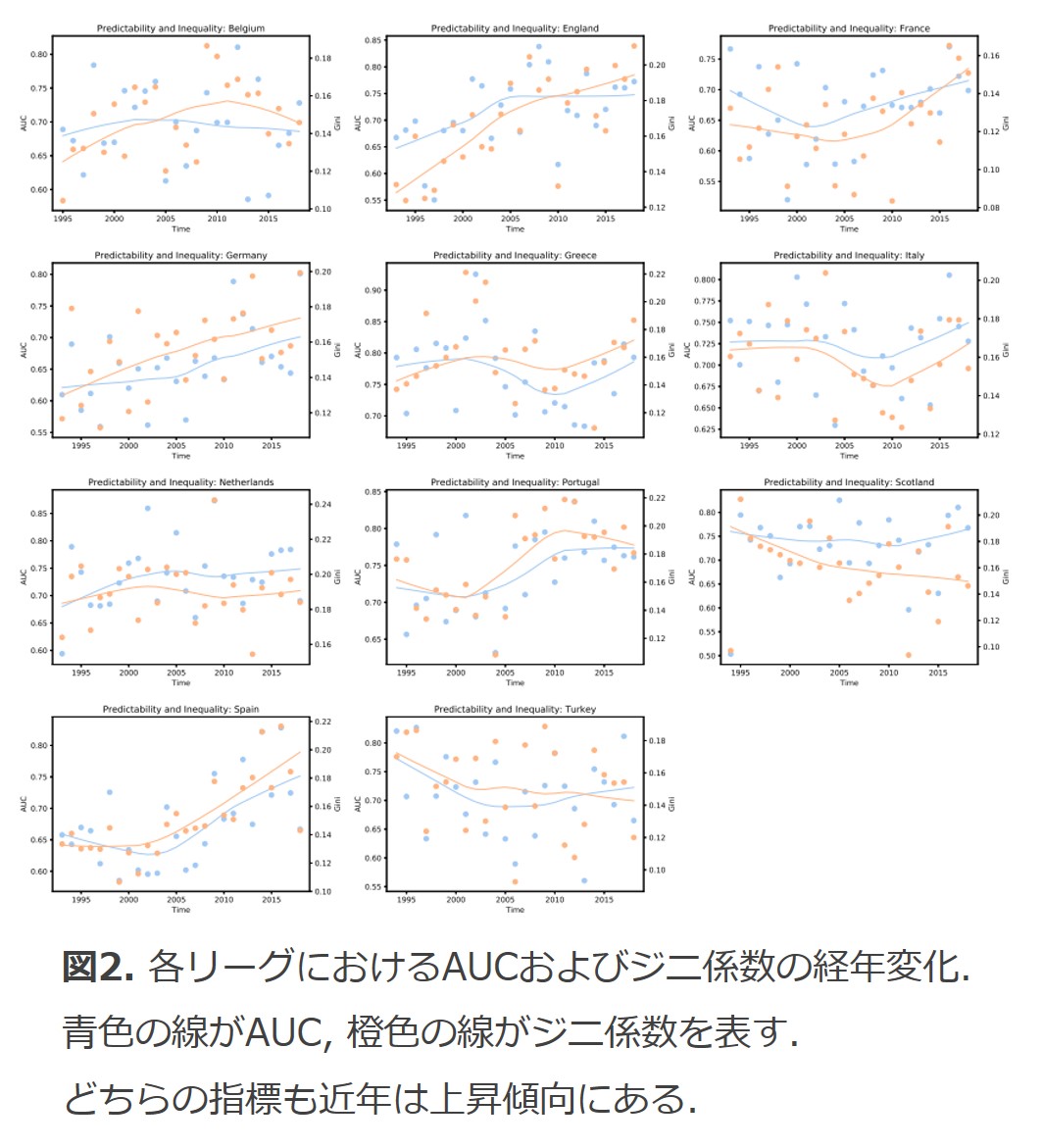
ほとんどのリーグにおいて、近年はAUCが上昇していることがわかります。
これは、最近の試合になるほど結果が予測しやすいことを示唆しています。
●格差があるリーグほど試合結果は予測しやすい
本研究では、AUCに加えてジニ係数も算出しています(赤色の線)。
ジニ係数は不平等さを表す指標であり、この数値が高いリーグ・年ほど、チーム間の実力差があることを意味します。
図2を見ると、ジニ係数の経年変化のパターンはAUCと似ているように思えます。
そこで彼らは、AUCとジニ係数の相関係数を調べることで、「試合の予測しやすさ」と「リーグ内の実力の不平等さ」に関係性があるのかについて調査しました。
以下の表のとおり、スペイン、イングランド、ドイツなどでは高い相関があったようです。
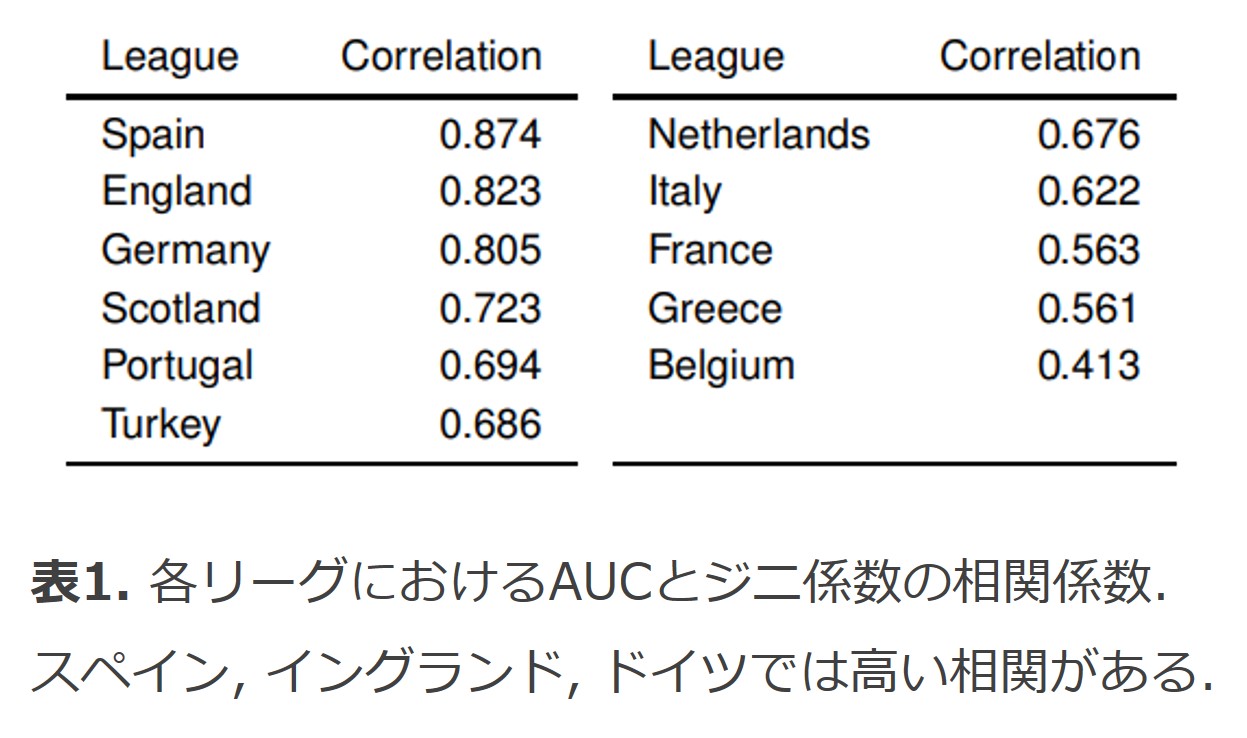
これは、チーム間の実力差があるリーグほど試合結果が予測しやすいことを意味しています(当たり前のような気もしますが...)。
上位3リーグはヨーロッパ内で最も市場規模が大きいリーグであることにも注目したいですね。
●まとめ
上記の結果を受け、Maimoneらは以下の結論を導いています。
時代に応じてサッカーは大きく変化している。
試合の「意外性」は減少し、チーム間の格差は増大している。
強いチームはより高い収益を得るため、より良い選手を獲得でき、さらに勝てるようになる。
年を経るたびにリーグのバランスは崩れていっており、試合結果も予測しやすくなっている。
非常にパワフルな結論ですが、論文をよく読むと問題点や課題があることに気が付きます。
・機械学習モデルによる判定を「意外性」の指標として用いることに対する妥当性。
・問題と計算をシンプルにするため、引き分けのパターンを考慮に入れていない点。
・全世界の試合データのうち約5%しか学習に使用していないため、サッカー界全体の傾向については結論を出すことができない点。
しかし、ファンが薄々感じていたことを根拠を持って示した点、各リーグの比較を行った点に本研究の価値がありますし、アプローチも斬新だと思います。
リーグ制を採用する競技全般に使える手法なので、Jリーグのデータでも試してみたいですね!
文:NAOKI
Twitter: @naokiwifruit
Columns

Graphics
2024-12-10 08:23
2024-12-03 15:43
2024-12-03 15:40